项目需求,需要分割出图片中积水区域,以及简单计算其面积,本次使用U-2-Net训练,并记录结果 U-2-Net官方github上面的pytorch是0.4.0版本,自己本地是1.8.0,起初以为出问题,不过最终训练过程却出奇的顺利
Git
数据集准备
训练代码默认使用DUTS数据集,下载后的标签如图

显著目标检测任务是将图像中的显著区域(前景)与非显著区域(背景)分割开来,结果用黑白图来表示,即前景用像素值255表示,背景用0来表示,一般的到的黑白图是1维的,所以如果要通过端到端来实现,那么模型的最后一个卷积层输出的通道数应该为1。这有点类似于语义分割的二分类任务,但是与语义分割不同的是,显著目标检测没有既定类别的分类对象,而语义分割则是有固定类别的分类任务,显著目标检测无法固定分类数,从结果图上看,显著目标检测(结果图为灰度图)更像是回归任务。
=====
接下来准备自己的标签,我的需求是分割出图片中有水的区域,最开始是使用所有包含积水的图片训练,但这样训练模型会将没有积水的区域也识别有积水,因此我增加了同一场景无积水的图作为负样本

修改代码
第一个错
负样本的标签即全图为背景,值都为0,因此默认的data_loader.py 会报错
ValueError: At least one stride in the given numpy array is negative, and tensors with negative strides are not currently supported. (You can probably work around this by making a copy of your array with array.copy().)
这个错误发生在你试图将一个有负步长的NumPy数组转换为PyTorch张量时。步长是在内存中跳过的字节数,以便在所有轴都为单位时,跳转到下一个元素。
在NumPy中,当数组是另一个被-1步长切片的数组的视图时,该数组可能有负步长。目前,PyTorch不支持负步长,因此会出现这个错误。
要解决这个问题,你可以在将NumPy数组转换为PyTorch张量之前复制一份你的NumPy数组。当你在一个NumPy数组上调用 .copy() 方法时,它会创建一个具有正步长的新数组。
在date_loader.py文件 ToTensorLab类中 修改即可
第二错
File "/home/user/anaconda3/envs/open-mmlab/lib/python3.7/site-packages/torch/utils/data/_utils/collate.py", line 55, in default_collate
return torch.stack(batch, 0, out=out)
RuntimeError: result type Double can't be cast to the desired output type Byte
这个错误出现在 torch.utils.data._utils.collate.default_collate 函数中,该函数用于将一个数据批次(batch)的数据堆叠在一起。该错误表明,你试图将一批类型为 Double 的数据堆叠起来,然后尝试将结果转换为 Byte 类型,但这种转换不被允许。
可以尝试自定义 collate_fn 函数来处理类型转换。例如,你可以创建一个函数,该函数接受一批数据,将其转换为 Double 类型,然后再进行堆叠。这个函数可以替代 default_collate 函数。然后,你可以在创建 DataLoader 时,将这个函数作为 collate_fn 参数传入。
修改后的文件代码如下
data_loader.py
# data loader
from __future__ import print_function, division
import glob
import torch
from skimage import io, transform, color
import numpy as np
import random
import math
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
from PIL import Image
#==========================dataset load==========================
class RescaleT(object):
def __init__(self,output_size):
assert isinstance(output_size,(int,tuple))
self.output_size = output_size
def __call__(self,sample):
imidx, image, label = sample['imidx'], sample['image'],sample['label']
h, w = image.shape[:2]
if isinstance(self.output_size,int):
if h > w:
new_h, new_w = self.output_size*h/w,self.output_size
else:
new_h, new_w = self.output_size,self.output_size*w/h
else:
new_h, new_w = self.output_size
new_h, new_w = int(new_h), int(new_w)
# #resize the image to new_h x new_w and convert image from range [0,255] to [0,1]
# img = transform.resize(image,(new_h,new_w),mode='constant')
# lbl = transform.resize(label,(new_h,new_w),mode='constant', order=0, preserve_range=True)
img = transform.resize(image,(self.output_size,self.output_size),mode='constant')
lbl = transform.resize(label,(self.output_size,self.output_size),mode='constant', order=0, preserve_range=True)
return {'imidx':imidx, 'image':img,'label':lbl}
class Rescale(object):
def __init__(self,output_size):
assert isinstance(output_size,(int,tuple))
self.output_size = output_size
def __call__(self,sample):
imidx, image, label = sample['imidx'], sample['image'],sample['label']
if random.random() >= 0.5:
image = image[::-1]
label = label[::-1]
h, w = image.shape[:2]
if isinstance(self.output_size,int):
if h > w:
new_h, new_w = self.output_size*h/w,self.output_size
else:
new_h, new_w = self.output_size,self.output_size*w/h
else:
new_h, new_w = self.output_size
new_h, new_w = int(new_h), int(new_w)
# #resize the image to new_h x new_w and convert image from range [0,255] to [0,1]
img = transform.resize(image,(new_h,new_w),mode='constant')
lbl = transform.resize(label,(new_h,new_w),mode='constant', order=0, preserve_range=True)
return {'imidx':imidx, 'image':img,'label':lbl}
class RandomCrop(object):
def __init__(self,output_size):
assert isinstance(output_size, (int, tuple))
if isinstance(output_size, int):
self.output_size = (output_size, output_size)
else:
assert len(output_size) == 2
self.output_size = output_size
def __call__(self,sample):
imidx, image, label = sample['imidx'], sample['image'], sample['label']
if random.random() >= 0.5:
image = image[::-1]
label = label[::-1]
h, w = image.shape[:2]
new_h, new_w = self.output_size
top = np.random.randint(0, h - new_h)
left = np.random.randint(0, w - new_w)
image = image[top: top + new_h, left: left + new_w]
label = label[top: top + new_h, left: left + new_w]
return {'imidx':imidx,'image':image, 'label':label}
class ToTensor(object):
"""Convert ndarrays in sample to Tensors."""
def __call__(self, sample):
imidx, image, label = sample['imidx'], sample['image'], sample['label']
tmpImg = np.zeros((image.shape[0],image.shape[1],3))
tmpLbl = np.zeros(label.shape)
image = image/np.max(image)
if(np.max(label)<1e-6):
label = label
else:
label = label/np.max(label)
if image.shape[2]==1:
tmpImg[:,:,0] = (image[:,:,0]-0.485)/0.229
tmpImg[:,:,1] = (image[:,:,0]-0.485)/0.229
tmpImg[:,:,2] = (image[:,:,0]-0.485)/0.229
else:
tmpImg[:,:,0] = (image[:,:,0]-0.485)/0.229
tmpImg[:,:,1] = (image[:,:,1]-0.456)/0.224
tmpImg[:,:,2] = (image[:,:,2]-0.406)/0.225
tmpLbl[:,:,0] = label[:,:,0]
tmpImg = tmpImg.transpose((2, 0, 1))
tmpLbl = label.transpose((2, 0, 1))
return {'imidx':torch.from_numpy(imidx), 'image': torch.from_numpy(tmpImg), 'label': torch.from_numpy(tmpLbl)}
class ToTensorLab(object):
"""Convert ndarrays in sample to Tensors."""
def __init__(self,flag=0):
self.flag = flag
self.label_fal = 1
def __call__(self, sample):
imidx, image, label =sample['imidx'], sample['image'], sample['label']
tmpLbl = np.zeros(label.shape)
if(np.max(label)<1e-6):
label = label
self.label_fal = 0
else:
label = label/np.max(label)
# change the color space
if self.flag == 2: # with rgb and Lab colors
tmpImg = np.zeros((image.shape[0],image.shape[1],6))
tmpImgt = np.zeros((image.shape[0],image.shape[1],3))
if image.shape[2]==1:
tmpImgt[:,:,0] = image[:,:,0]
tmpImgt[:,:,1] = image[:,:,0]
tmpImgt[:,:,2] = image[:,:,0]
else:
tmpImgt = image
tmpImgtl = color.rgb2lab(tmpImgt)
# nomalize image to range [0,1]
tmpImg[:,:,0] = (tmpImgt[:,:,0]-np.min(tmpImgt[:,:,0]))/(np.max(tmpImgt[:,:,0])-np.min(tmpImgt[:,:,0]))
tmpImg[:,:,1] = (tmpImgt[:,:,1]-np.min(tmpImgt[:,:,1]))/(np.max(tmpImgt[:,:,1])-np.min(tmpImgt[:,:,1]))
tmpImg[:,:,2] = (tmpImgt[:,:,2]-np.min(tmpImgt[:,:,2]))/(np.max(tmpImgt[:,:,2])-np.min(tmpImgt[:,:,2]))
tmpImg[:,:,3] = (tmpImgtl[:,:,0]-np.min(tmpImgtl[:,:,0]))/(np.max(tmpImgtl[:,:,0])-np.min(tmpImgtl[:,:,0]))
tmpImg[:,:,4] = (tmpImgtl[:,:,1]-np.min(tmpImgtl[:,:,1]))/(np.max(tmpImgtl[:,:,1])-np.min(tmpImgtl[:,:,1]))
tmpImg[:,:,5] = (tmpImgtl[:,:,2]-np.min(tmpImgtl[:,:,2]))/(np.max(tmpImgtl[:,:,2])-np.min(tmpImgtl[:,:,2]))
# tmpImg = tmpImg/(np.max(tmpImg)-np.min(tmpImg))
tmpImg[:,:,0] = (tmpImg[:,:,0]-np.mean(tmpImg[:,:,0]))/np.std(tmpImg[:,:,0])
tmpImg[:,:,1] = (tmpImg[:,:,1]-np.mean(tmpImg[:,:,1]))/np.std(tmpImg[:,:,1])
tmpImg[:,:,2] = (tmpImg[:,:,2]-np.mean(tmpImg[:,:,2]))/np.std(tmpImg[:,:,2])
tmpImg[:,:,3] = (tmpImg[:,:,3]-np.mean(tmpImg[:,:,3]))/np.std(tmpImg[:,:,3])
tmpImg[:,:,4] = (tmpImg[:,:,4]-np.mean(tmpImg[:,:,4]))/np.std(tmpImg[:,:,4])
tmpImg[:,:,5] = (tmpImg[:,:,5]-np.mean(tmpImg[:,:,5]))/np.std(tmpImg[:,:,5])
elif self.flag == 1: #with Lab color
tmpImg = np.zeros((image.shape[0],image.shape[1],3))
if image.shape[2]==1:
tmpImg[:,:,0] = image[:,:,0]
tmpImg[:,:,1] = image[:,:,0]
tmpImg[:,:,2] = image[:,:,0]
else:
tmpImg = image
tmpImg = color.rgb2lab(tmpImg)
# tmpImg = tmpImg/(np.max(tmpImg)-np.min(tmpImg))
tmpImg[:,:,0] = (tmpImg[:,:,0]-np.min(tmpImg[:,:,0]))/(np.max(tmpImg[:,:,0])-np.min(tmpImg[:,:,0]))
tmpImg[:,:,1] = (tmpImg[:,:,1]-np.min(tmpImg[:,:,1]))/(np.max(tmpImg[:,:,1])-np.min(tmpImg[:,:,1]))
tmpImg[:,:,2] = (tmpImg[:,:,2]-np.min(tmpImg[:,:,2]))/(np.max(tmpImg[:,:,2])-np.min(tmpImg[:,:,2]))
tmpImg[:,:,0] = (tmpImg[:,:,0]-np.mean(tmpImg[:,:,0]))/np.std(tmpImg[:,:,0])
tmpImg[:,:,1] = (tmpImg[:,:,1]-np.mean(tmpImg[:,:,1]))/np.std(tmpImg[:,:,1])
tmpImg[:,:,2] = (tmpImg[:,:,2]-np.mean(tmpImg[:,:,2]))/np.std(tmpImg[:,:,2])
else: # with rgb color
tmpImg = np.zeros((image.shape[0],image.shape[1],3))
image = image/np.max(image)
if image.shape[2]==1:
tmpImg[:,:,0] = (image[:,:,0]-0.485)/0.229
tmpImg[:,:,1] = (image[:,:,0]-0.485)/0.229
tmpImg[:,:,2] = (image[:,:,0]-0.485)/0.229
else:
tmpImg[:,:,0] = (image[:,:,0]-0.485)/0.229
tmpImg[:,:,1] = (image[:,:,1]-0.456)/0.224
tmpImg[:,:,2] = (image[:,:,2]-0.406)/0.225
tmpLbl[:,:,0] = label[:,:,0]
tmpImg = tmpImg.transpose((2, 0, 1))
tmpLbl = label.transpose((2, 0, 1))
if self.label_fal ==0:
tmpLbl = tmpLbl.copy()
return {'imidx':torch.from_numpy(imidx), 'image': torch.from_numpy(tmpImg), 'label': torch.from_numpy(tmpLbl)}
class SalObjDataset(Dataset):
def __init__(self,img_name_list,lbl_name_list,transform=None):
# self.root_dir = root_dir
# self.image_name_list = glob.glob(image_dir+'*.png')
# self.label_name_list = glob.glob(label_dir+'*.png')
self.image_name_list = img_name_list
self.label_name_list = lbl_name_list
self.transform = transform
def __len__(self):
return len(self.image_name_list)
def __getitem__(self,idx):
# image = Image.open(self.image_name_list[idx])#io.imread(self.image_name_list[idx])
# label = Image.open(self.label_name_list[idx])#io.imread(self.label_name_list[idx])
image = io.imread(self.image_name_list[idx])
imname = self.image_name_list[idx]
imidx = np.array([idx])
if(0==len(self.label_name_list)):
label_3 = np.zeros(image.shape)
else:
label_3 = io.imread(self.label_name_list[idx])
label = np.zeros(label_3.shape[0:2])
if(3==len(label_3.shape)):
label = label_3[:,:,0]
elif(2==len(label_3.shape)):
label = label_3
if(3==len(image.shape) and 2==len(label.shape)):
label = label[:,:,np.newaxis]
elif(2==len(image.shape) and 2==len(label.shape)):
image = image[:,:,np.newaxis]
label = label[:,:,np.newaxis]
sample = {'imidx':imidx, 'image':image, 'label':label}
if self.transform:
sample = self.transform(sample)
return sample
train_own.py
import os
import torch
import torchvision
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
import torch.optim as optim
import torchvision.transforms as standard_transforms
import numpy as np
import glob
import os
from data_loader import Rescale
from data_loader import RescaleT
from data_loader import RandomCrop
from data_loader import ToTensor
from data_loader import ToTensorLab
from data_loader import SalObjDataset
from model import U2NET
from model import U2NETP
# ------- 1. define loss function --------
bce_loss = nn.BCELoss(size_average=True)
def muti_bce_loss_fusion(d0, d1, d2, d3, d4, d5, d6, labels_v):
loss0 = bce_loss(d0,labels_v)
loss1 = bce_loss(d1,labels_v)
loss2 = bce_loss(d2,labels_v)
loss3 = bce_loss(d3,labels_v)
loss4 = bce_loss(d4,labels_v)
loss5 = bce_loss(d5,labels_v)
loss6 = bce_loss(d6,labels_v)
loss = loss0 + loss1 + loss2 + loss3 + loss4 + loss5 + loss6
print("l0: %3f, l1: %3f, l2: %3f, l3: %3f, l4: %3f, l5: %3f, l6: %3f\n"%(loss0.data.item(),loss1.data.item(),loss2.data.item(),loss3.data.item(),loss4.data.item(),loss5.data.item(),loss6.data.item()))
return loss0, loss
# ------- 2. set the directory of training dataset --------
model_name = 'u2net' #'u2netp'
# data_dir = os.path.join(os.getcwd(), 'train_data' + os.sep)
# tra_image_dir = os.path.join('DUTS', 'DUTS-TR', 'DUTS-TR', 'im_aug' + os.sep)
# tra_label_dir = os.path.join('DUTS', 'DUTS-TR', 'DUTS-TR', 'gt_aug' + os.sep)
data_dir = os.path.join('/opt/data_al/20230801_u2net_waterZone/' + os.sep)
tra_image_dir = os.path.join('images' + os.sep)
tra_label_dir = os.path.join('labels' + os.sep)
image_ext = '.jpg'
label_ext = '.png'
model_dir = os.path.join(os.getcwd(), 'saved_models', model_name + os.sep)
epoch_num = 10000
batch_size_train = 8
batch_size_val = 1
train_num = 0
val_num = 0
tra_img_name_list = glob.glob(data_dir + tra_image_dir + '*' + image_ext)
tra_lbl_name_list = []
for img_path in tra_img_name_list:
img_name = img_path.split(os.sep)[-1]
aaa = img_name.split(".")
bbb = aaa[0:-1]
imidx = bbb[0]
for i in range(1,len(bbb)):
imidx = imidx + "." + bbb[i]
tra_lbl_name_list.append(data_dir + tra_label_dir + imidx + label_ext)
print("---")
print("train images: ", len(tra_img_name_list))
print("train labels: ", len(tra_lbl_name_list))
print("---")
def my_collate_fn(batch):
images = [item['image'].to(torch.double) for item in batch]
labels = [item['label'].to(torch.double) for item in batch]
imidxs = [item['imidx'].to(torch.double)for item in batch]
return {'imidx': torch.stack(imidxs, 0), 'image': torch.stack(images, 0), 'label': torch.stack(labels, 0)}
train_num = len(tra_img_name_list)
salobj_dataset = SalObjDataset(
img_name_list=tra_img_name_list,
lbl_name_list=tra_lbl_name_list,
transform=transforms.Compose([
RescaleT(320),
RandomCrop(288),
ToTensorLab(flag=0)]))
salobj_dataloader = DataLoader(salobj_dataset, batch_size=batch_size_train, shuffle=True, num_workers=1,collate_fn=my_collate_fn)
# ------- 3. define model --------
# define the net
if(model_name=='u2net'):
net = U2NET(3, 1)
elif(model_name=='u2netp'):
net = U2NETP(3,1)
if torch.cuda.is_available():
net.cuda()
# ------- 4. define optimizer --------
print("---define optimizer...")
optimizer = optim.Adam(net.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
# ------- 5. training process --------
print("---start training...")
ite_num = 0
running_loss = 0.0
running_tar_loss = 0.0
ite_num4val = 0
save_frq = 2000 # save the model every 2000 iterations
for epoch in range(0, epoch_num):
net.train()
for i, data in enumerate(salobj_dataloader):
ite_num = ite_num + 1
ite_num4val = ite_num4val + 1
inputs, labels = data['image'], data['label']
inputs = inputs.type(torch.FloatTensor)
labels = labels.type(torch.FloatTensor)
# wrap them in Variable
if torch.cuda.is_available():
inputs_v, labels_v = Variable(inputs.cuda(), requires_grad=False), Variable(labels.cuda(),
requires_grad=False)
else:
inputs_v, labels_v = Variable(inputs, requires_grad=False), Variable(labels, requires_grad=False)
# y zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
d0, d1, d2, d3, d4, d5, d6 = net(inputs_v)
loss2, loss = muti_bce_loss_fusion(d0, d1, d2, d3, d4, d5, d6, labels_v)
loss.backward()
optimizer.step()
# # print statistics
running_loss += loss.data.item()
running_tar_loss += loss2.data.item()
# del temporary outputs and loss
del d0, d1, d2, d3, d4, d5, d6, loss2, loss
print("[epoch: %3d/%3d, batch: %5d/%5d, ite: %d] train loss: %3f, tar: %3f " % (
epoch + 1, epoch_num, (i + 1) * batch_size_train, train_num, ite_num, running_loss / ite_num4val, running_tar_loss / ite_num4val))
if ite_num % save_frq == 0:
torch.save(net.state_dict(), model_dir + model_name+"_bce_itr_%d_train_%3f_tar_%3f.pth" % (ite_num, running_loss / ite_num4val, running_tar_loss / ite_num4val))
running_loss = 0.0
running_tar_loss = 0.0
net.train() # resume train
ite_num4val = 0
训练
python train_own.py 即可开始训练,不过感觉训练得有点慢,且官方库没有 resume这个功能
测试
infer.py
官方库测试的话出来最终只有mask图片,我根据提供的demo简单写了一个mask覆盖在原图的方法
import cv2
import torch
from model import U2NET
from torch.autograd import Variable
import numpy as np
from glob import glob
import os
from skimage import io, transform
from PIL import Image
def normPRED(d):
ma = torch.max(d)
mi = torch.min(d)
dn = (d-mi)/(ma-mi)
return dn
def rescale_image(image, output_size):
h, w = image.shape[:2]
if isinstance(output_size, int):
if h > w:
new_h, new_w = output_size * h / w, output_size
else:
new_h, new_w = output_size, output_size * w / h
else:
new_h, new_w = output_size
new_h, new_w = int(new_h), int(new_w)
img = transform.resize(image, (output_size, output_size), mode='constant')
return img
def to_tensor(image):
tmpImg = np.zeros((image.shape[0],image.shape[1],3))
image = image / np.max(image)
if image.shape[2] == 1:
tmpImg[:,:,0] = (image[:,:,0] - 0.485) / 0.229
tmpImg[:,:,1] = (image[:,:,0] - 0.485) / 0.229
tmpImg[:,:,2] = (image[:,:,0] - 0.485) / 0.229
else:
tmpImg[:,:,0] = (image[:,:,0] - 0.485) / 0.229
tmpImg[:,:,1] = (image[:,:,1] - 0.456) / 0.224
tmpImg[:,:,2] = (image[:,:,2] - 0.406) / 0.225
tmpImg = tmpImg.transpose((2, 0, 1))
return torch.from_numpy(tmpImg)
def save_output_after(image_name,pred,d_dir):
predict = pred
predict = predict.squeeze()
predict_np = predict.cpu().data.numpy()
im = Image.fromarray(predict_np*255).convert('RGB')
img_name = image_name.split(os.sep)[-1]
image = io.imread(image_name)
imo = im.resize((image.shape[1],image.shape[0]),resample=Image.BILINEAR)
pb_np = np.array(imo)
print("imagename:",image_name)
aaa = img_name.split(".")
bbb = aaa[0:-1]
imidx = bbb[0]
for i in range(1,len(bbb)):
imidx = imidx + "." + bbb[i]
imo.save(d_dir+imidx+'.png')
def save_output_after_cv(image_name, pred, d_dir):
predict = pred
predict = predict.squeeze()
predict_np = predict.cpu().data.numpy()
# Scale prediction to range 0-255 and convert to 3-channel (BGR)
predict_np = cv2.cvtColor((predict_np * 255).astype('uint8'), cv2.COLOR_GRAY2BGR)
img_name = image_name.split(os.sep)[-1]
image = cv2.imread(image_name)
# Resize the prediction to original image size
imo = cv2.resize(predict_np, (image.shape[1], image.shape[0]), interpolation=cv2.INTER_LINEAR)
ret, binary = cv2.threshold(imo.astype(np.uint8), 125, 255, cv2.THRESH_BINARY)
# Normalize imo back to range [0,1]
# imo_normalized = imo.astype('float') / 255
mask = binary.astype(bool)[:,:,0]
print("mask:",mask.shape)
color_mask = np.array([[128, 64, 128]])
image[mask] = image[mask] * 0.5 + color_mask * 0.5
print("imagename:", image_name)
aaa = img_name.split(".")
bbb = aaa[0:-1]
imidx = bbb[0]
for i in range(1, len(bbb)):
imidx = imidx + "." + bbb[i]
#回显结果
cv2.imwrite(d_dir + imidx + '.png', image)
# # Save the image
cv2.imwrite(d_dir + imidx + '_mask.png', imo)
def inference(net,input):
tmpImg = rescale_image(input,(320))
print("tmpImgResize:",tmpImg.shape)
tmpImg =to_tensor(tmpImg)
tmpImg = tmpImg[np.newaxis, :, :, :]
tmpImg = tmpImg.type(torch.FloatTensor)
print("tmpImgtensor:", tmpImg.shape)
# # normalize the input
# input = cv2.resize(input, (320,320), interpolation = cv2.INTER_AREA)
# # rescale_image(input,(320))
# tmpImg = np.zeros((320,320,3))
# input = input/np.max(input)
#
#
# tmpImg[:, :, 0] = (input[:, :, 0] - 0.485) / 0.229
# tmpImg[:, :, 1] = (input[:, :, 1] - 0.456) / 0.224
# tmpImg[:, :, 2] = (input[:, :, 2] - 0.406) / 0.225
#
#
# # convert BGR to RGB
# tmpImg = tmpImg.transpose((2, 0, 1))
# tmpImg = tmpImg[np.newaxis,:,:,:]
# tmpImg = torch.from_numpy(tmpImg)
#
# # convert numpy array to torch tensor
# tmpImg = tmpImg.type(torch.FloatTensor)
if torch.cuda.is_available():
tmpImg = Variable(tmpImg.cuda())
else:
tmpImg = Variable(tmpImg)
# inference
d1,d2,d3,d4,d5,d6,d7= net(tmpImg)
# normalization
# pred = 1.0 - d1[:,0,:,:]
pred = d1[:, 0, :, :]
pred = normPRED(pred)
# # convert torch tensor to numpy array
# pred = pred.squeeze()
# pred = pred.cpu().data.numpy()
del d1,d2,d3,d4,d5,d6,d7
return pred
def main():
im_list = glob('/opt/algorithm_code/U-2-Net-master/test_data/test_waterZone_images/*')
print("Number of images: ", len(im_list))
out_dir = '/opt/algorithm_code/U-2-Net-master/test_data/own_infer/'
if (not os.path.exists(out_dir)):
os.mkdir(out_dir)
model_dir = r"/opt/algorithm_code/U-2-Net-master/saved_models/u2net/u2net_bce_itr_34000_train_0.106161_tar_0.011368.pth"
# load u2net_portrait model
net = U2NET(3,1)
net.load_state_dict(torch.load(model_dir))
if torch.cuda.is_available():
net.cuda()
net.eval()
# do the inference one-by-one
for i in range(0,len(im_list)):
print("--------------------------")
print("inferencing ", i, "/", len(im_list), im_list[i])
# load each image
# img = cv2.imread(im_list[i])
img = io.imread(im_list[i])
im_portrait = inference(net,img)
# save the output
# cv2.imwrite(out_dir+"/"+im_list[i].split('/')[-1][0:-4]+'.png',(im_portrait*255).astype(np.uint8))
save_output_after_cv(im_list[i], im_portrait, out_dir)
if __name__ == '__main__':
main()
需要注意的时,我本来用opencv 进行预处理,但是效果没有skimage的好 (因为训练时候用的skimage库) 但是我拿到mask后,需要用opencv的方法进行处理,所以会看到我预处理用的skimage,保存图片时用的opencv
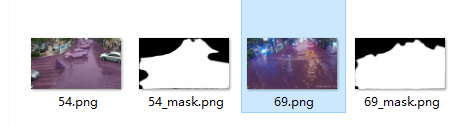
最终测试效果